Note
Go to the end to download the full example code.
XOR classification
A simple example for getting started with emlearn.
Will train a RandomForestClassifier model on a XOR dataset, generate C code for this model using emlearn Python package, load this model in C and make predictions using it.
import os.path
import emlearn
import numpy
import pandas
import seaborn
import matplotlib.pyplot as plt
try:
# When executed as regular .py script
here = os.path.dirname(__file__)
except NameError:
# When executed as Jupyter notebook / Sphinx Gallery
here = os.getcwd()
Create dataset
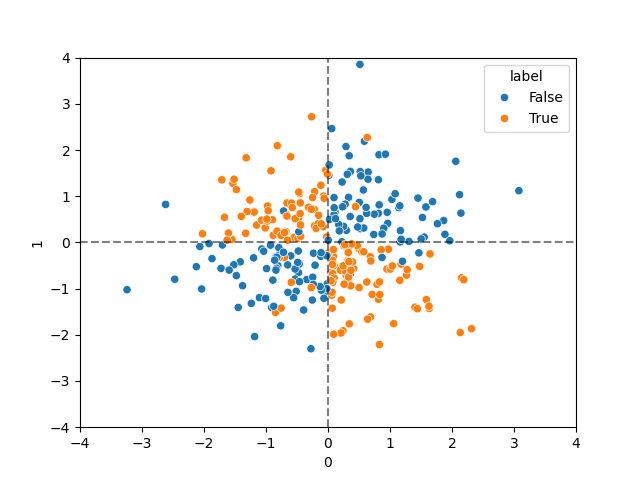
The XOR problem is a very simple example of a dataset which is not linearly separable.
def make_noisy_xor(seed=42):
xx, yy = numpy.meshgrid(numpy.linspace(-3, 3, 500),
numpy.linspace(-3, 3, 500))
rng = numpy.random.RandomState(seed)
X = rng.randn(300, 2)
y = numpy.logical_xor(X[:, 0] > 0, X[:, 1] > 0)
# Add some noise
flip = rng.randint(300, size=15)
y[flip] = ~y[flip]
df = pandas.DataFrame((X * 255).astype(numpy.int16))
df['label'] = y
return df
def dataset_split_random(data, val_size=0.25, test_size=0.25, random_state=3, column='split'):
"""
Split DataFrame into 3 non-overlapping parts: train,val,test with specified proportions
Returns a new DataFrame with the rows marked by the assigned split in @column
"""
train_size = (1.0 - val_size - test_size)
from sklearn.model_selection import train_test_split
train_val_idx, test_idx = train_test_split(data.index, test_size=test_size, random_state=random_state)
val_ratio = (val_size / (val_size+train_size))
train_idx, val_idx = train_test_split(train_val_idx, test_size=val_ratio, random_state=random_state)
data = data.copy()
data.loc[train_idx, column] = 'train'
data.loc[val_idx, column] = 'val'
data.loc[test_idx, column] = 'test'
return data
dataset = make_noisy_xor()
dataset = dataset_split_random(dataset, test_size=0.10).set_index('split')
# Plot the dataset
ax = seaborn.scatterplot(data=dataset, x=0, y=1, hue='label')
ax.axvline(0.0, ls='--', alpha=0.5, color='black')
ax.axhline(0.0, ls='--', alpha=0.5, color='black')
ax.set_xlim(-4.0*255, +4.0*255)
ax.set_ylim(-4.0*255, +4.0*255)
# Show colums of the data
print(dataset.head(5))
0 1 label
split
val 126 -35 True
val 165 388 False
val -59 -59 False
train 402 195 False
train -119 138 True
Train ML model
Usin the standard process with scikit-learn
def train_model(dataset, seed=42):
from sklearn.ensemble import RandomForestClassifier
#feature_columns =
X_train = dataset.loc['train', [0, 1]]
Y_train = dataset.loc['train', 'label']
model = RandomForestClassifier(n_estimators=10, max_depth=5, random_state=seed)
model.fit(X_train, Y_train)
return model
model = train_model(dataset)
Convert model to C using emlearn
def convert_model(model):
model_filename = os.path.join(here, 'xor_model.h')
cmodel = emlearn.convert(model)
code = cmodel.save(file=model_filename, name='xor')
assert os.path.exists(model_filename)
print(f"Generated {model_filename}")
convert_model(model)
Generated /home/docs/checkouts/readthedocs.org/user_builds/emlearn/checkouts/latest/examples/xor_model.h
Use generated C model to make predictions
xor.c : Executable that takes features as commandline arguments, and prints the predicted class to stdout
#include "xor_model.h" // emlearn generated model
#include <stdio.h> // printf
#include <stdlib.h> // stdod
int
main(int argc, const char *argv[])
{
if (argc != 3) {
return -1;
}
// Input is espected to be 0.0-255.0
const float a = strtod(argv[1], NULL);
const float b = strtod(argv[2], NULL);
// Convert to integers
const int16_t features[] = { a, b };
const int out = xor_predict(features, 2);
if (out < 0) {
return out; // error
} else {
printf("%d\n", out);
}
}
# Python wrapper for the C executable
# calls the C program as a subprocess to run the model
def predict(bin_path, X, verbose=1):
import subprocess
def predict_one(x):
args = [ bin_path, str(x[0]), str(x[1]) ]
out = subprocess.check_output(args)
cls = int(out)
if verbose > 0:
print(f"run xor in1={x[0]:+.2f} in2={x[1]:+.2f} out={cls} ")
return cls
y = [ predict_one(x) for x in numpy.array(X) ]
return numpy.array(y)
def evaluate_model(dataset):
# Compile the xor.c example program
out_dir = './examples'
src_path = os.path.join(here, 'xor.c')
include_dirs = [ emlearn.includedir ]
bin_path = emlearn.common.compile_executable(src_path, out_dir, include_dirs=include_dirs)
print('Compiled C excutable', bin_path)
# Make predictions on dataset
X_test = dataset.loc['test', [0, 1]]
Y_test = dataset.loc['test', 'label']
y_pred_c = predict(bin_path, X_test)
y_pred_py = model.predict(X_test)
# Compute scores using converted C model, and original Python model
import sklearn.metrics
f1_score_c = sklearn.metrics.f1_score(Y_test, y_pred_c)
f1_score_py = sklearn.metrics.f1_score(Y_test, y_pred_py)
print(f'\nF1-score python={f1_score_py} c={f1_score_c}')
evaluate_model(dataset)
Compiled C excutable ./examples/main
run xor in1=-118.00 in2=-118.00 out=0
run xor in1=-3.00 in2=-269.00 out=0
run xor in1=+82.00 in2=-98.00 out=1
run xor in1=-282.00 in2=-305.00 out=0
run xor in1=+357.00 in2=-357.00 out=1
run xor in1=-395.00 in2=+17.00 out=1
run xor in1=-234.00 in2=+395.00 out=1
run xor in1=+475.00 in2=+120.00 out=0
run xor in1=+209.00 in2=+483.00 out=0
run xor in1=-62.00 in2=-192.00 out=0
run xor in1=+131.00 in2=+131.00 out=0
run xor in1=-123.00 in2=+20.00 out=1
run xor in1=-186.00 in2=+55.00 out=1
run xor in1=-516.00 in2=+47.00 out=1
run xor in1=-112.00 in2=+33.00 out=1
run xor in1=+139.00 in2=-51.00 out=1
run xor in1=+295.00 in2=+201.00 out=0
run xor in1=-4.00 in2=-255.00 out=0
run xor in1=-336.00 in2=+467.00 out=1
run xor in1=+1.00 in2=+11.00 out=1
run xor in1=-63.00 in2=+247.00 out=1
run xor in1=-246.00 in2=+174.00 out=1
run xor in1=-301.00 in2=-520.00 out=0
run xor in1=+383.00 in2=+18.00 out=0
run xor in1=-135.00 in2=-202.00 out=0
run xor in1=-141.00 in2=-305.00 out=0
run xor in1=-264.00 in2=-48.00 out=0
run xor in1=-356.00 in2=+143.00 out=1
run xor in1=+12.00 in2=-211.00 out=1
run xor in1=+83.00 in2=-55.00 out=1
F1-score python=0.967741935483871 c=0.967741935483871
Total running time of the script: (0 minutes 0.164 seconds)