Note
Go to the end to download the full example code.
Voting options for trees
This example illustrates hard majority voting vs soft voting options for trees.
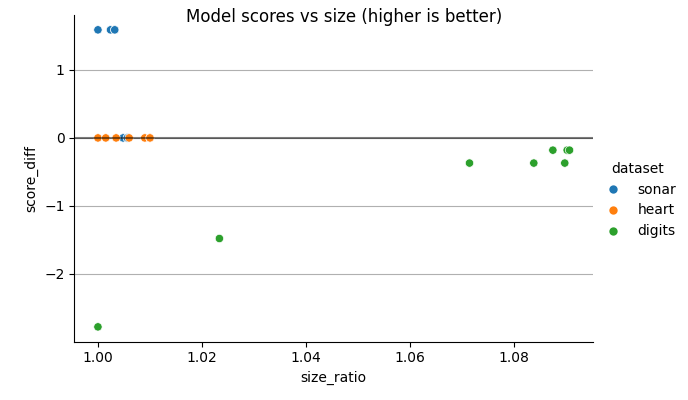
Hard voting can sometimes give a significant drop in predictive performance, and using soft voting can be neccesary to match the original model. This makes the model slightly bigger.
import os.path
import emlearn
import numpy
import pandas
import seaborn
import matplotlib.pyplot as plt
try:
# When executed as regular .py script
here = os.path.dirname(__file__)
except NameError:
# When executed as Jupyter notebook / Sphinx Gallery
here = os.getcwd()
Load datasets
from sklearn.datasets import fetch_openml, load_digits
from emlearn.examples.datasets.sonar import load_sonar_dataset
sonar_data = load_sonar_dataset()
heart_data, y = fetch_openml('heart-statlog', version=1, as_frame=True, return_X_y=True)
heart_data['label'] = y
digits_data, y = load_digits(as_frame=True, return_X_y=True)
digits_data['label'] = y
print('sonar', len(sonar_data))
print('heart', len(heart_data))
print('digits', len(digits_data))
sonar 208
heart 270
digits 1797
Train a RandomForest model
Key thing is to transform the data into integers that fit the
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from sklearn.model_selection import cross_val_score, StratifiedKFold, train_test_split
#from sklearn.metrics import get_scorer
from sklearn.metrics import accuracy_score
def prepare_data(data, label_column = 'label'):
feature_columns = list(set(data.columns) - set([label_column]))
X = data[feature_columns]
Y = data[label_column]
# Rescale and convert to integers (quantize)
# Here everything is made to fit in int16
X = (MinMaxScaler().fit_transform(X) * 2**15-1).astype(int)
Y = LabelEncoder().fit_transform(Y)
return X, Y
def train_model(data, max_depth=5):
X, Y = prepare_data(data)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.30)
model = RandomForestClassifier(n_estimators=10, max_depth=max_depth, random_state=1)
# sanity check performance
cv = StratifiedKFold(5, random_state=None, shuffle=False)
scores = cross_val_score(model, X_train, Y_train, cv=cv, scoring='accuracy')
assert numpy.mean(scores) >= 0.70, (numpy.mean(scores), scores)
model.fit(X_train, Y_train)
#Y_pred = model.predict_proba(X_test)[:, 1]
Y_pred = model.predict(X_test)
#test_score = average_precision_score(Y_test, Y_pred, pos_label=pos_label)
test_score = accuracy_score(Y_test, Y_pred)
assert test_score >= 0.70, test_score
return model, X_test, Y_test
Experiments with different leaf_bits settings
from emlearn.evaluate.trees import model_size_bytes, model_size_leaves
def run_experiment(leaf_bits, X_test, Y_test, model):
# Do conversion with specified leaf_bits
c_model = emlearn.convert(model, method='loadable', leaf_bits=leaf_bits)
#model_code = c_model.save(name=model_name, include_proba=True)
# As a reference, compute the score before conversion
Y_pred_ref = model.predict(X_test)
ref_score = accuracy_score(Y_test, Y_pred_ref)
# Estimate predictive performance after conversion
Y_pred = c_model.predict(X_test)
score = accuracy_score(Y_test, Y_pred)
# Estimate model size
model_size = model_size_bytes(c_model)
model_leaves = model_size_leaves(c_model)
out = pandas.Series({
'model_size_bytes': model_size,
'model_leaves': model_leaves,
'leaf_bits': leaf_bits,
'score': round(100*score, 2),
'ref_score': round(100*ref_score, 2),
})
out['score_diff'] = out['score'] - out['ref_score']
return out
experiments = pandas.DataFrame({
'leaf_bits': [0,2,3,4,5,6,7,8],
})
Sonar dataset
model, X_test, Y_test = train_model(sonar_data, max_depth=6)
sonar_results = experiments.leaf_bits.apply(run_experiment, X_test=X_test, Y_test=Y_test, model=model)
sonar_results['dataset'] = 'sonar'
sonar_results['size_ratio'] = sonar_results['model_size_bytes'] / sonar_results['model_size_bytes'].min()
print(sonar_results)
model_size_bytes model_leaves leaf_bits ... score_diff dataset size_ratio
0 1240.0 2.0 0.0 ... 1.59 sonar 1.000000
1 1243.0 3.0 2.0 ... 1.59 sonar 1.002419
2 1244.0 4.0 3.0 ... 1.59 sonar 1.003226
3 1244.0 4.0 4.0 ... 1.59 sonar 1.003226
4 1246.0 6.0 5.0 ... 0.00 sonar 1.004839
5 1246.0 6.0 6.0 ... 0.00 sonar 1.004839
6 1247.0 7.0 7.0 ... 0.00 sonar 1.005645
7 1247.0 7.0 8.0 ... 0.00 sonar 1.005645
[8 rows x 8 columns]
Heart disease dataset
model, X_test, Y_test = train_model(heart_data, max_depth=6)
heart_results = experiments.leaf_bits.apply(run_experiment, X_test=X_test, Y_test=Y_test, model=model)
heart_results['dataset'] = 'heart'
heart_results['size_ratio'] = heart_results['model_size_bytes'] / heart_results['model_size_bytes'].min()
print(heart_results)
model_size_bytes model_leaves leaf_bits ... score_diff dataset size_ratio
0 2000.0 2.0 0.0 ... 0.0 heart 1.0000
1 2003.0 3.0 2.0 ... 0.0 heart 1.0015
2 2007.0 7.0 3.0 ... 0.0 heart 1.0035
3 2012.0 12.0 4.0 ... 0.0 heart 1.0060
4 2018.0 18.0 5.0 ... 0.0 heart 1.0090
5 2020.0 20.0 6.0 ... 0.0 heart 1.0100
6 2020.0 20.0 7.0 ... 0.0 heart 1.0100
7 2020.0 20.0 8.0 ... 0.0 heart 1.0100
[8 rows x 8 columns]
Digits dataset
model, X_test, Y_test = train_model(digits_data, max_depth=5)
digits_results = experiments.leaf_bits.apply(run_experiment, X_test=X_test, Y_test=Y_test, model=model)
digits_results['dataset'] = 'digits'
digits_results['size_ratio'] = digits_results['model_size_bytes'] / digits_results['model_size_bytes'].min()
print(digits_results)
model_size_bytes model_leaves leaf_bits ... score_diff dataset size_ratio
0 2184.0 10.0 0.0 ... -2.78 digits 1.000000
1 2235.0 51.0 2.0 ... -1.48 digits 1.023352
2 2340.0 156.0 3.0 ... -0.37 digits 1.071429
3 2367.0 183.0 4.0 ... -0.37 digits 1.083791
4 2375.0 191.0 5.0 ... -0.18 digits 1.087454
5 2380.0 196.0 6.0 ... -0.37 digits 1.089744
6 2381.0 197.0 7.0 ... -0.18 digits 1.090201
7 2382.0 198.0 8.0 ... -0.18 digits 1.090659
[8 rows x 8 columns]
Visualize results
Soft voting gives slightly bigger models, but often good improvements in predictive performance.
def plot_results(results):
results = results.reset_index()
g = seaborn.relplot(data=results,
#kind='bar',
y='score_diff',
x='size_ratio',
hue='dataset',
height=4,
aspect=1.5,
)
fig = g.figure
fig.suptitle("Model scores vs size (higher is better)")
for ax in g.axes.flat:
ax.grid(True, which='major', axis='y')
ax.axhline(0.0, ls='-', lw=1.5, color='black', alpha=0.5)
ax.set_axisbelow(True)
return fig
combined = pandas.concat([sonar_results, heart_results, digits_results], axis=0)
fig = plot_results(combined)
fig.savefig('example-trees-voting.png')
Total running time of the script: (0 minutes 8.675 seconds)